Essential Statistics for data science tutorial ( Descriptive, Inferential)
If you want to became a data scientist, Statistics is mandatory part of the course. In this article, we will cover statistics that are required for data science.
What is Statistics:
Statistics is the science of collecting, organizing, presenting, analyzing and interpreting data to help in making more effective decision.
What is statistical analysis :
Statistical analysis is implemented to manipulate, summarize and investigate data, so that useful decision-making information results are obtained.
Types of statistics:
There are 2 types of statistics.
- Descriptive statistics : It is a method of organizing, summarizing, and presenting data in information way.
- Inferential statistics: It is a method which is used in determining something about a population on the basis of a simple.
What is population in statistics?
The entire set of individuals or objects of interest or the measurements obtained from all individuals or objects interest.
What is sample in statistics ?
A portion, or part of the population of interest.
What are Basic Terms in statistics?
Variable – A characteristic about each individual element of a population/sample
Data(singular) – A value of the associated variable with one element of a population/sample. This values may be a number, a word, or a symbol.
Data(plural) – A set of values collected for the variable from each of the elements belonging to the sample.
Experiment – A planned activity whose results yield a set of data.
Parameter – A numerical value which summarizes the entire population data.
Statistic – A numerical value which summarizes the sample data.
Types of Variables:
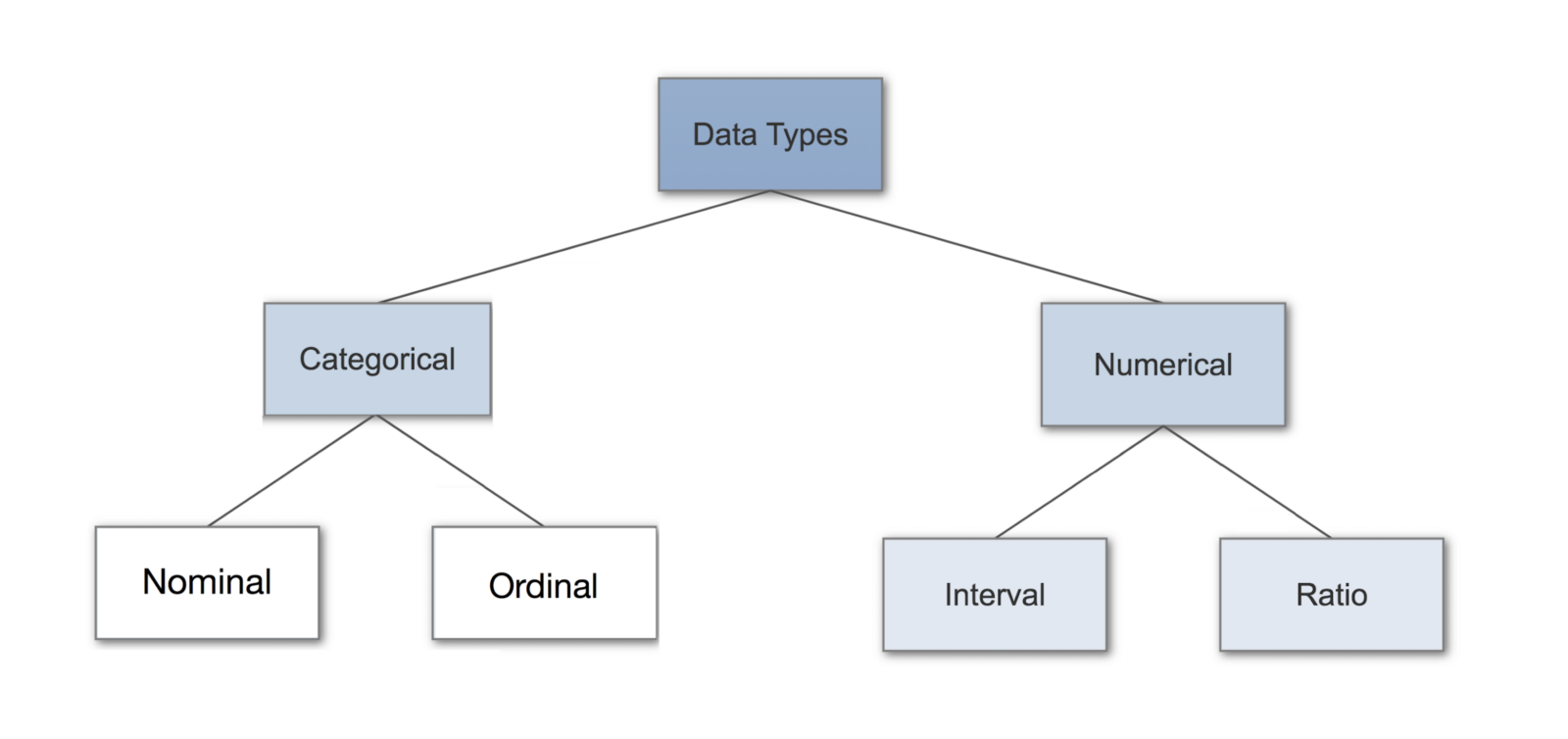
Qualitative variables: A variable that categories or describes a population of element. (Numerical data)
Example: Weight of the person, No of people in car
Discrete Variable : Natural numbers – A discrete variable is a variable that can only take on a certain number of values. In other words, they don’t have an infinite number of values
Continuous Variable : A continuous variable is a variable that has an infinite number of possible values. In other words, any value is possible for the variable. A continuous variable is the opposite of a discrete variable, which can only take on a certain number of values
Qualitative variable: A variable that quantifies a population element. ( Categorical)
Example: Color, Gender, Yes/no
Nominal Variables: Categorical variable with out order.
Example: M/F, Yes/no
Ordinal Variables : Categorical variable with order
Example: Rating(1 – 5)
Types of statistical measures:
- Measures of frequency
- Measures of central tendency
- Measures of spread
- Measures of position
Measures of frequency: Frequency statistics simply count the number of times that each variable occurs within the sample.
Measures of central tendency: It indicates whether the data values accumulate in the middle of distribution or towards the end.
Example: Mean, Mode Median.
What is mean in statistics ?
It’s the average value from the data. We can calculate by simply sum of all the variables and divide by the no of variables.
Mean = ( sum of the number of variables)/no of variables
Example : data= [1,2,4,5,6,7]
Mean = (1+2+4+5+6+7)/6 ->4.1666
Mean is used when the data is continuous and discrete.
What is Mode in statistics ?
Mode is most repeated values in the dataset. ( highest frequency)
What is Median in statistics ?
The median is the middle value of the ordered data.
formula: mean-mode = 3(mean-median)
Measures of spread or dispersion : It characterize how to spread out the distribution. i.e how variable data are.
Range , variance and standard deviation are the measures of the dispersion.
Range : The difference between maximum value and minimum value. (max-min)
Chebysheff’s theorem: Chebyshev’s theorem will show you how to use the mean and the standard deviation to find the percentage of the total observations that fall within a given interval about the mean.
Chebyshev’s theorem:
For any number k greater than 1, at least ( 1 – frac{1}{{k^2}} ) of the data values lie k standard deviations of the mean.
Set theorem : Set theory is a branch of mathematical logic that studies sets, which informally are collections of objects. Although any type of object can be collected into a set, set theory is applied most often to objects that are relevant to mathematics
Types of distribution in statistics:
- Bernoulli Distribution
- Uniform Distribution
- Binomial Distribution
- Normal Distribution
- Poisson Distribution
- Exponential Distribution
What is normal distribution ?
A) It’s like a bell curve distribution. Mean, Mode and Medium are equal in this distribution. Most of the distributions in statistics are normal distribution.
What is standard normal distribution ?
If mean is 0 and standard deviation is 1 then we call that distribution as standard normal distribution.
What is Binominal Distribution ?
A distribution where only two outcomes are possible, such as success or failure and where the probability of success and failure is same for all the trials then it is called a Binomial Distribution
What is Bernoulli distribution ?
A Bernoulli distribution has only two possible outcomes, namely 1 (success) and 0 (failure), and a single trial.
What is Poisson distribution ?
A distribution is called Poisson distribution when the following assumptions are true:
1. Any successful event should not influence the outcome of another successful event.
2. The probability of success over a short interval must equal the probability of success over a longer interval.
3. The probability of success in an interval approaches zero as the interval becomes smaller.
What is central limit theorem ?
a) Mean of sample means is closely to the mean of the population
b) Standard deviation of the sample distribution can be found out from the population standard deviation divided by square root of sample size N and it is also known as standard error of means.
c) if the population is not normal distribution, but the sample size is greater than 30 the sampling distribution of sample means approximates a normal distribution
What is P Value, How it’s useful ?
The p-value is the level of marginal significance within a statistical hypothesis test representing the probability of the occurrence of a given event.
- If The p-value is less than 0.05 (p<=0.05), It indicates strong evidence against the null hypothesis, you can reject the Null Hypothesis
- If the P-value is higher than 0.05 (p>0.05), It indicates weak evidence against the null hypothesis, you can fail to reject the null Hypothesis
What is Z value or Z score (Standard Score) , How it’s useful ?
Z score indicates how many standard deviations on element is from the mean. It is also called standard score.
Z score Formula
z = (X – μ) / σ
- It is useful in Statistical testing.
- Z-value is range between -3 to 3.
- Its useful to find the outliers in large data
What is T-Score, What is the use of it ?
- It is a ratio between the difference between two groups and the difference within the groups. The larger t score, the more difference there is between groups. The smaller t-score means the more similarity between groups.
- We can use t-score when the sample size is less than 30, It is used in statistical testing
What is IQR ( Interquartile Range ) and Usage ?
- It is difference between 75th and 25th percentiles, or between upper and lower quartiles,
- It is also called Misspread data or Middle 50%.
- Mainly to find outliers in data, if the observations that fall below Q1 − 1.5 IQR or above Q3 + 1.5 IQR those are considered as outliers.
Formula IQR = Q3-Q1
What is Hypothesis Testing ?
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis
How many Types of Hypothesis Testing are there ?
- Null Hypothesis, Alternative Hypothesis
What is Type 1 Error ?
FP – False Positive ( In statistics it is the rejection of a true null hypothesis)
What is Type 2 Error ?
FN – False Negative ( In statistics it is failing to reject a false null hypothesis)
What is population ?
It is a discrete group of people, animals or things that can be identified by at least one common characteristic for the purposes of data collection and analysis
What is sampling ?
Sampling is a process used in statistical analysis in which a predetermined number of observations are taken from a larger population
Types of sampling techniques ?
There are two major types of sampling
1. PROBABILITY SAMPLING
- Simple Random Sampling
- Stratified Random Sampling
- Systematic Sampling
- Cluster Sampling
- Multi-stage Sampling
2. NON-PROBABILITY SAMPLING
- Purposive Sampling
- Convenience Sampling
- Snow-ball Sampling
- Quota Sampling
What is Sample Bias ?
It is a type of bias caused by choosing non-random data for statistical analysis
What is Selection Bias ?
Selection bias is usually introduced as an error with the sampling and having a selection for analysis that is not properly randomized
What is Univariate, Bivariate, Multi Variate Analysis ?
Univarite means single variable – Analysis on single variable data
Bivariate means two variables – you can do analysis on multiple variables
Mutli Variate means multiple variables – Analysis on multiple variables



